;) Sahelian forest in Mali, courtesy Wikimedia
Sahelian forest in Mali, courtesy Wikimedia
This is a guest post by Doug Keenan.
In August, the journal Nature Climate Change published a piece by a researcher at the Earth Institute of Columbia University. The researcher, Alessandra Giannini, is an expert on precipitation in the Sahel, and her piece was on that topic.
Giannini’s piece notes that Sahel precipitation has been slightly increasing during the past few decades, but then warns as follows.
… a gap in research: a complete understanding of the influence of [greenhouse gases], direct and indirect, on the climate of the Sahel. This is needed more urgently…. While precipitation may have recovered in the seasonal total amount, it has done so through more intense, but less frequent precipitation events. This state of affairs requires more attention be paid to the climate of the Sahel, to ensure that negotiations around adaptation, such as those taking place in the run-up to the Conference of the Parties of the UN Framework Convention on Climate Change that will be held in Paris at the end of this year, are based on the best science available….
Even though precipitation is increasing, and even though intense rainfall is often beneficial (because it penetrates deep into the soil), the piece has a strong alarmist tone. As that might suggest, Giannini is an environmental activist: indeed, she has prominently participated in demonstrations for “climate change action”.
Giannini’s piece was the subject of a post at Bishop Hill: “Duelling models”. The post noted some apparent problems with Giannini’s piece, in particular with the statistical analyses. After seeing the post, I wrote to Giannini, to discuss the statistical analyses. Giannini and I then had a brief e-mail exchange. A copy of the exchange is below.
_____________________
My first message to Giannini was the following.
In your paper “Hydrology: Climate change comes to the Sahel” (just published in Nature), Figure 1 displays Sahel precipitation anomalies for 1979–2008. The figure’s caption gives some correlations and the significance levels of those correlations. How were the correlations calculated? In particular, what orders of autocorrelation were used?
Giannini kindly replied the same day, as follows.
The correlations are plain, vanilla, Pearson correlations -- something like this:
<http://glossary.ametsoc.org/wiki/Correlation>
No estimation of autocorrelation was taken into account.
Just to clarify, the time series are anomalies of the July-September average rainfall computed with respect to the 1979-2008 climatology.
July to September is the core of the rainy season in the Sahel. Rainy seasons are separated by a prolonged dry season during which it rarely if ever rains.
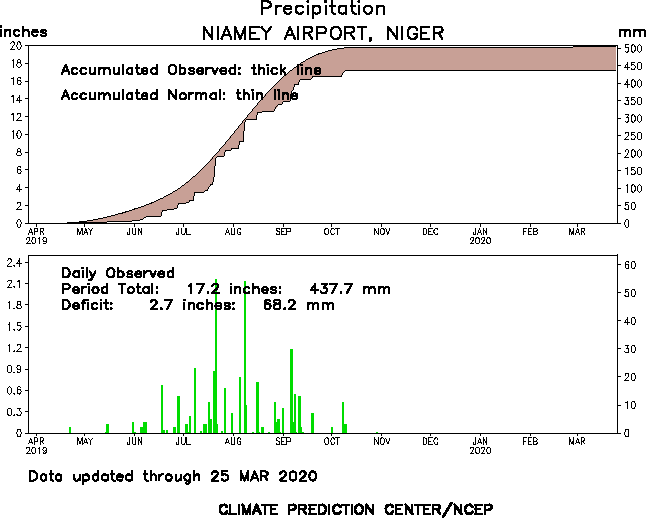
Here is an example of a daily precipitation time series, from Niamey, Niger - the last 365 days on record:
<http://www.cpc.ncep.noaa.gov/products/global_monitoring/precipitation/sn61052_1yr.gif>
The observed values I used in the calculation can be downloaded from here:
The modeled values can be obtained through the CMIP5 archive:
or I should say, you will be able to obtain them once the data portal is back online…
{kind=link}
I responded as follows.
Your message is much appreciated. The correlations that you calculated seem fine. The issue is with the significance levels (or confidence intervals).
From the observed values, it is clear that if a given year is especially wet (or dry), then that increases the chance that the next year is above-averagely wet (or dry). In other words, the observed series is autocorrelated. The calculations of significance that you did assumed that autocorrelation was 0. Thus, the calculations are inaccurate.
For some background on this, see
http://www.ltrr.arizona.edu/~dmeko/notes_9.pdf
I got the observed values easily, from the link that you kindly included. Would you be willing to send me the 30 multi-model ensemble mean values?
Relatedly, I was curious—what is the reason that the data stops in 2008?
Giannini kindly replied the next day.
I understand. Usually we worry about autocorrelation when a time series exhibits persistence, which would mean that this year's above average precipitation increases the chances that next year's will also be above average, whereas you are pointing to a negative auto-correlation.
Statistically, the correlation with 1-year lag as I computed it comes to 0.24 in the observed time series I shared, which by the same token used in the article is not significant with the same level of confidence.
Maybe we need to compare notes…
In the past, the time series of Sahel rainfall has shown more persistence year-to-year, which had to do with persistence in the oceanic forcing of Sahel rainfall - decades of persistently above average followed by decades of persistently below average [drought] conditions. But that seems to be no more, hence what you correctly observed as swings year-to-year.
The next thing to do would be to come up with a physical hypothesis as to why the swings…
Extracting the multi-model ensemble-mean time series requires a lot more work. It is non-trivial, often under appreciated, grunt work for any climate scientist who wishes to analyze the CMIP/IPCC simulations, hence my reason for pointing you to the CMIP5 archive…
The analysis stops in 2008 because the specific model simulations used were run over 1979-2008.
My response was the following.
I am happy to receive your comments. ….
For the observed time series, the lag-1 autocorrelation is not known. Suppose we assume that the data is generated by a first-order autoregressive Gaussian process (this assumption is actually an unjustifiable simplification). Then the autocorrelation coefficient has a maximum likelihood estimate of 0.24 (the value cited in your message), a 68% confidence interval of [0.04, 0.41], and a 95% confidence interval of [-0.14, 0.55]. The confidence intervals are fairly wide mainly because the time series is short.
Given the above, when considering how much autocorrelation could plausibly affect the conclusions, a reasonable conservative value is the upper limit of the 68% confidence interval: 0.41. That value would seem to be large enough to affect the conclusions, depending on the autocorrelation of the modelled series.
About the underlying physical mechanisms, I am largely ignorant. I was only considering the statistical analysis. My suspicion is that statistical analysis will not be very useful here, though, and physical simulations are required.
About the 30 multi-model ensemble mean values, I realize that obtaining them involves work. The web site for the data seems to be down for the next month, though; also, I assume that you have the values, as you did calculations with them(!). Would you be willing to send them?
Giannini did not reply to that.
Ten days after sending the preceding message, I sent the one below.
I did not receive a reply to my last message; you should have at least sent me the 30 data values. In any case, regarding the claim in your piece that the “multi-model ensemble mean correlation with observations is … significant at the 5% level”, it seems clear that the claim is false—once the autocorrelations are considered.
Your piece additionally claims that the “correlation of the ensemble mean of 5 simulations with GFDL-CM3 … is 0.58, significant at the 1% level”. The data for GFDL-CM3 is also unavailable to me. Your piece, however, includes a figure that displays the data: I obtained fairly-precise data values via reading off the figure.
The maximum likelihood estimate for the correlation that I got was 0.58, i.e. the same as you got. That correlation is so high that it is significant even after the autocorrelations are considered. The correlation, however, is still not actually significant—due to a second error in your piece’s calculations.
To understand the second error, suppose that we compared the observed time series with, say, 50 other random time series. Then the observed series might well significantly correlate with a few of the random series, just by chance. Generally, whenever we compare a single series to multiple series, we need to consider that some of the comparisons might appear to be significant just due to chance. For an amusing explanation of the issue, not specific to time series, see the “Significant” cartoon at xkcd:
http://xkcd.com/882/The multiple-comparisons issue is discussed in the time-series course notes that I linked to earlier:
http://www.ltrr.arizona.edu/~dmeko/notes_9.pdfThe notes recommend that, when doing multiple comparisons, the significance levels be obtained via the “Bonferroni adjustment”. There is also a more general discussion of the issue in Wikipedia:
https://en.wikipedia.org/wiki/Multiple_comparisons_problem—which lists the Bonferroni adjustment as one of several methods to address the issue.
When you compared the observed series to the different modeled series, the multiple-comparisons issue arises. There were 62 different models used, if I have understood the CMIP5 documentation correctly:
http://cmip-pcmdi.llnl.gov/cmip5/docs/CMIP5_modeling_groups.pdfSome adjustment needs to be made for that. Whatever method is used to make the adjustment, it seems clear that after both making the adjustment and considering the autocorrelations, the claim—about the correlation between observations and GFDL-CM3 being significant—is invalid.
Your piece further claims that GFDL-CM3 is a better model than HadGEM2 for Sahel precipitation. That claim is very dubious for the same reason: the higher correlation with GFDL-CM3 might be just due to essentially random noise.
I did not receive a reply to that.
There is one issue that merits elaboration, perhaps. Suppose that we have 30 measurements from some time series, a1, a2, a3, …, a30, and 30 measurements from some other time series, b1, b2, b3, …, b30. Suppose further that we want to know the correlation of the two series. There are computer programs available that, given the two 30-element inputs, will output what is called the “correlation” of the two series. The correlation that is output by such programs is sometimes misinterpreted.
Each of the two series is usually part of a potentially much longer series: a1, a2, a3, …, an, and b1, b2, b3, …, bn, for some large n. In other words, each of the 30-element inputs is actually just a sample from a much longer series. What we are really interested in, in general, is the correlation of the longer series.
There is no way to know, for certain, the correlation of the longer series. What we can do, however, is estimate the correlation of the longer series, from the 30-element samples. Typically, when making the estimate, we should determine what the most likely value for the correlation is, as well as, say, the 95%-confidence interval and the 68%-confidence interval (or similar likelihood intervals). What some computer programs output is just the most likely value for the correlation of the longer series—and this is sometimes misinterpreted as the actual correlation of the longer series, when it is really only an estimate.
Reference
Giannini A. (2015), “Climate change comes to the Sahel”, Nature Climate Change, 5: 720–721; doi:10.1038/nclimate2739.